1. 들어가며
- 저번 포스트에서 JDBC를 사용한 데이터 저장, 조회, 수정, 삭제를 구현하였다.
- 이번 포스트에서는 트랜젝션이라는 개념을 배우기 이전에 커넥션 풀이라는 개념에 대해 먼저 알아보고 간다.
2. 커넥션 획득 과정

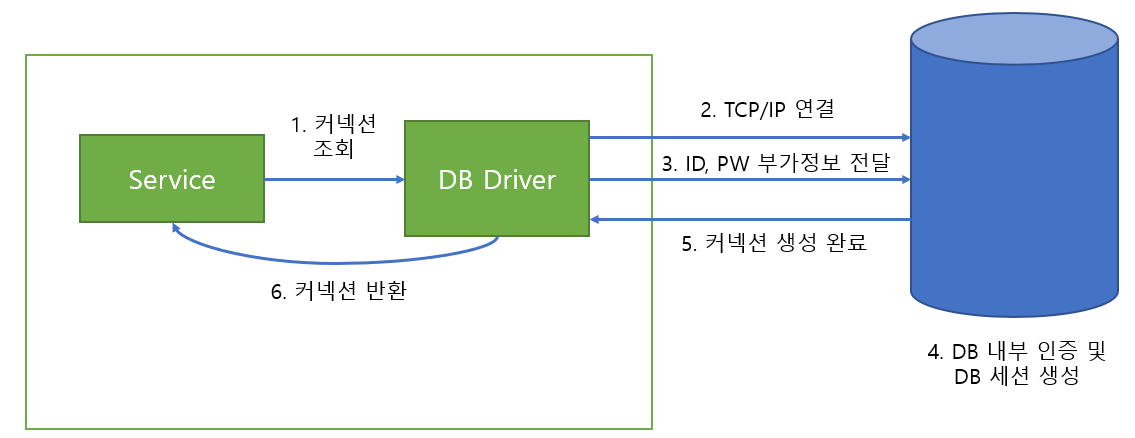
- 어떤 요청이 들어왔을 때 DB 커넥션이 필요한 경우 다음과 같은 방식을 통해 커넥션을 연결한다.
- 먼저 DB 드라이버에 현재 사용 가능한 커넥션이 존재하는지 조회한다.
- 이 단계에서 만약 사용 가능한 커넥션이 존재한다면 해당 커넥션을 반환하고 과정이 종료된다.
- 이후 사용 가능한 커넥션이 없다면 DB 드라이버는 DB에 TCP/IP 연결을 수행한다.
- TCP/IP 연결이 성립되면 ID, PW를 전송한다.
- DB는 받은 ID와 PW를 사용하여 사용자 인증을 수행하고, 해당 연결에 대한 DB 세션을 생성한다. 이후에 DB 드라이버에 생성된 커넥션을 반환한다.
- 이후 드라이버는 해당 커넥션을 반환한다.
- 먼저 DB 드라이버에 현재 사용 가능한 커넥션이 존재하는지 조회한다.
- 문제점은 해당 과정이 "모든 요청"에 대해 수행된다는 것이다. 우리가 구현했던 데이터 CRUD 레포지토리를 생각해보라. 매 번 커넥션을 생성하고 받은 뒤, 요청을 수행하고 해당 커넥션을 닫았다.
- 추가적인 커넥션을 생성해 보관하지도 않았기 때문에 매번 새로운 커넥션이 생성되어야 하고, 매번 위의 과정들이 모두 수행되어야 한다. 이는 요청 트레픽이 많아질수록 성능에 영향을 주게 된다.
- TCP/IP의 3-way 핸드쉐이크부터 시작하여 내부 인증 및 세션 생성은 매우 코스트가 많이 들어간다.
- 당장 HTTP에서도 TCP 연결이 매번 수행되어야 하는 번거로움 때문에 클라이언트와 서버간 연결을 한 번 수행하고 그 동안 HTML, CSS 등의 데이터들을 모두 요청하는 방식으로 수행할 정도이다.
3. 커넥션 풀(Connection Pool)
- 위의 문제 역시 우리가 어디선가 맞닥드린적이 있는 문제이다. 요청에 대해 매번 새롭게 객체를 생성하는 비효율성 문제이다.
- 스프링은 해당 문제를 객체를 미리 생성하고 해당 객체를 반환하는 형식으로 해결하였다. 우리는 객체를 "미리" 생성하는 것에 주목해보자.
- 서버가 올라갈 때 커넥션을 미리 여러 개를 만드는 것이다. 그리고 DB사용 요청이 들어오면 해당 커넥션을 요청 클라이언트에게 넘겨주면 된다. 클라이언트는 해당 커넥션을 모두 사용한 뒤에 커넥션의 집합에 다시 커넥션을 반환한다.
- 해당 방식을 사용하면 서비스 로직이 DB를 사용해야 할 때 커넥션을 조회하고 연결을 수행하는 여러 과정이 모두 필요 없이 바로 커넥션을 가져와 사용할 수 있다.
- 즉 위의 연결을 위한 수많은 과정들이 모두 사라진다. 해당 과정들은 모두 서버가 시작될 때 미리 수행되어 커넥션들이 커넥션 집합에 들어가기 때문이다.
- 이 커넥션 집합을 커넥션 풀(Connection Pool)이라고 한다.
4. 커넥션 풀의 용량과 사용 모듈
- 일반적으로 톰캣에서 커넥션 풀의 용량은 10으로 잡고 있다. 즉 기본 세팅으로 톰캣 서버를 사용할 경우에 커넥션 풀에는 최대 10개의 커넥션들이 저장될 수 있다는 것이다.
- 물론 최대 용량을 조정할 수도 있다. 너무 많이 사용할 경우 자원 사용에 대한 압박이 커질수도 있고, 너무 적게 사용할 경우 병목이 발생할 수도 있으니 성능 테스트와 여러 스펙을 고려한 뒤에 조정해야 한다.
- 커넥션 풀의 최대 용량보다 더 많은 커넥션이 생성된다면 예외를 내보낼 수 있다. 이 점은 DB에 계속해서 커넥션이 생성되는 것을 막음으로서 DB보호의 효과도 가질 수 있다.
- 보통 커넥션 풀은 오픈소스를 사용하며 스프링부트에서는 HikariCP를 사용하고 있다
'Spring & JPA > JDBC' 카테고리의 다른 글
| JDBC - JDBC 커넥션 풀 - DataSource 적용 (0) | 2023.06.05 |
|---|---|
| JDBC - JDBC 커넥션 풀 - DataSource (0) | 2023.06.05 |
| JDBC - JDBC 사용 - 3. 데이터 수정과 삭제 (0) | 2023.06.03 |
| JDBC - JDBC 사용 - 2. 데이터 조회 (0) | 2023.06.03 |
| JDBC - JDBC사용 - 1. 데이터 저장 (0) | 2023.06.03 |