class BinarySearchTree{
Node root;
BinarySearchTree(){
this.root = null;
}
public void addNode(int key){
}
public boolean searchNode(int key){
}
public void removeNode(int key){
}
public void traversal(Node cur){
if (cur == null){
return;
}
traversal(cur.left);
System.out.print(cur.data + " ");
traversal(cur.right);
}
}
순회의 경우 이전에 이미 구현한 적이 있으므로 여기서는 이미 구현되어 있다고 가정한다.
데이터의 삽입
데이터의 삽입은 이진 탐색 트리의 원리인 대소 비교를 통해 삽입할 위치를 찾는 것에서 부터 시작된다.
루트부터 시작해 삽입할 데이터의 값과 트리에 존재하는 값을 비교한다.
이때 삽입할 데이터의 값 < 현재 위치의 데이터 값 이라면 삽입할 위치는 현재 위치에서 좌측으로 이동한다.
삽입할 데이터의 값 > 현재 위치의 데이터 값 이라면 삽입할 위치는 현재 위치에서 우측으로 이동한다.
이후 이동한 위치가 null로 비어있는 공간이라면 새로운 노드를 만들어 달아주면 종료된다.
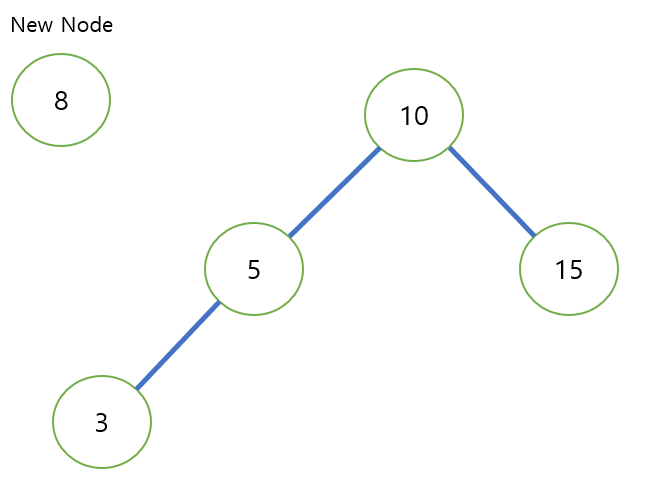
간단한 그림으로 예시를 들면 아래와 같은 상황이 있다고 가정하자.
이진 탐색 트리에 원소를 삽입
이 경우, 8은 우선 root인 10와 대소비교를 수행한다. 8 < 10이기 때문에 원소가 삽입될 장소는 10의 좌측인 5로 이동하게 된다.
원소가 삽입되는 장소인 cur과 부모 노드를 가리키는 pre
이후 8은 삽입될 장소를 가리키는 cur에 저장된 5와 대소비교를 수행한다. 8 > 5 이기 때문에 cur은 5의 우측으로 이동하게 된다.
이때 cur는 null을 가리킨다. 그림에서 보듯이 5의 우측 자식은 null로 존재하지 않기 때문이다.
따라서 이 장소는 8을 저장하는데 적합해 보인다. 하지만 링크를 잇는데 cur로는 부족하다. 이전 위치를 기억해야하는 포인터가 하나 더 필요하다.
이를 위해 pre가 존재한다. pre는 cur의 직전 노드를 가리키기 때문에 pre.right = new Node(key)라는 구문으로 링크를 이으면서 새로운 노드를 만들어 붙일 수 있다.
pre를 통해 새로운 노드와 부모 노드 간 링크가 설정된 사진
해당 과정을 코드로 옮기면 아래와 같다.
public void addNode(int key){
if (root == null){
root = new Node(key);
return;
}
if (searchNode(key)){
return;
}
Node cur = this.root;
while (true){
Node pre = cur;
if (cur.data < key){
cur = cur.right;
if (cur == null){
pre.right = new Node(key);
break;
}
} else{
cur = cur.left;
if (cur == null){
pre.left = new Node(key);
break;
}
}
}
}
searchNode(key)는 해당 노드가 이미 트리에 존재하는지를 확인하는데 사용한다. 이전에도 서술했지만 BST는 중복된 데이터를 허용하지 않는다.
정리
이번에는 원소의 삽입을 알아보았다. 다음에는 원소의 삭제에 대해 구현해 볼 것이다 원소의 삭제는 삽입보다 더 까다롭다. 그리고 노드가 존재하는지 탐색하는 searchNode 역시 다음 시간에 구현해 볼 것이다.