트라이는 문자열을 저장하고 빠르게 탐색하기 위해 사용하는 자료구조의 일종으로 트리 구조를 가진다.
일반적으로 어떠한 문자열에서 특정 문자열을 찾기 위해서 이중 루프를 사용하나 해당 방법은 O(N^2)에 가까운 수행시간이 걸리게 된다.
트라이에서는 트라이 자료구조를 생성하는데 걸리는 시간 O(MN)이 수행된다(M : 문자열의 개수, N : 문자열의 길이) 하지만 생성하고 나면 길이 N의 문자열을 탐색하는데 O(N)이 수행되며 트라이 자료구조를 위한 메모리와 탐색에 걸리는 시간을 trade-off 하였다고 할 수 있다.
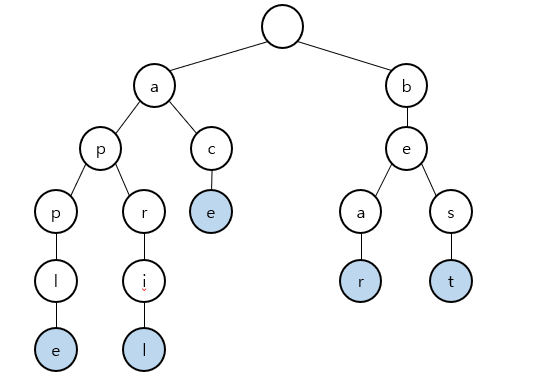
트라이 자료구조의 예시
위 사진의 트라이에는 각각 "apple", "april", "ace", "bear", "best"가 들어가있다. 푸른색으로 색칠된 노드들은 해당 노드가 문자열의 끝임을 나타내는 표시이다.
여기서 트라이의 특징이 하나 더 보이는데 공통된 철자들은 그대로고 다른 철자들만 가지로 뻗어나가는 것을 확인할 수 있다.
트라이의 구현
트라이는 트리의 구조인 만큼 노드를 사용하여 구현한다. 다만 노드가 일반적인 노드와는 그 형태가 조금 다르다. 노드는 Map자료구조를 활용한다.
class Node{
HashMap<Character, Node> child;
boolean isTerminal;
Node(){
this.child = new HashMap<>();
this.isTerminal = false;
}
}
key로는 문자열의 한 철자로, 그 값은 그 문자열의 철자로 파생되는 자식 노드들로 하는 Map 자료구조를 사용하며 해당 노드가 문자열의 끝을 의미하는지를 나타내는 isTerminal 변수가 있다.
트라이의 연산은 삽입과 삭제, 탐색이 있으며 전체적인 형태는 아래와 같다.
class Trie{
Node root;
Trie(){
this.root = new Node();
}
public void insert(String str){
}
public boolean search(String str){
}
public void delete(String str){
}
public boolean delete(Node node, String str, int idx){
}
}
트라이의 구현 - 삽입 연산
트라이에 들어가는 문자열은 그 철자 하나하나가 모두 노드로 변환되어 트라이에 삽입되게 된다.
예시를 들어 "apple"이 트라이에 저장되는 과정을 살펴보자 맨 처음에는 a가 트라이에 저장되어야 한다. 만약 트라이에 a라는 노드가 이미 존재한다면 삽입 연산을 더 수행할 필요가 없을 것이다.
현재 트라이의 상태는 비어있는 상태이기 때문에, a는 루트와 연결될 것이다.
위와 같은 과정을 거쳐 e가 이제 삽입될 차례이다. e는 해당 문자열의 마지막이기 때문에 삽입된 뒤 해당 노드가 마지막 노드라는 것을 알리면 된다.
public void insert(String str){
Node cur = root;
for (int i = 0; i < str.length(); i++){
char c = str.charAt(i);
cur.child.putIfAbsent(c, new Node());
cur = cur.child.get(c);
if (i == str.length() - 1){
cur.isTerminal = true;
}
}
}
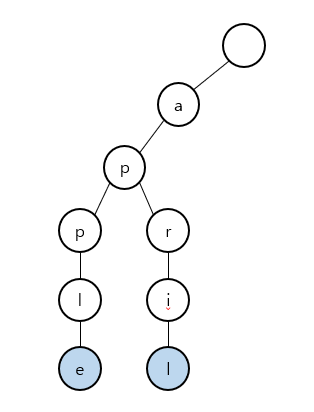
"apple"을 넣은 트라이의 상태는 아래와 같다.
"apple"이 들어간 트라이의 상태
만약 여기서 "app"이 삽입된다면 어떨까? 그렇다면 모든 철자들이 이미 존재하기 때문에 노드의 추가는 없고 app의 마지막 철자인 p가 isTerminal = true가 되도록 설정이 될 것이다.
동일한 로직으로 "april"이 트라이에 삽입된 결과는 아래와 같다.
"april"이 추가된 후의 트라이 상태
트라이의 구현 - 탐색 연산
가장 중요한 트라이의 탐색 연산을 구현해보자.
로직 자체는 삽입과 꽤 유사한데, 입력으로 받은 스트링을 철자 하나씩 확인하면서 해당 노드가 존재하는지 확인하는 과정을 계속 거치다 마지막 부분에서 문자열의 마지막 부분임을 나타내는 isTerminal이 true인지를 확인하면 된다.
만약 isTerminal이 false 상태라면 해당 문자가 문자열의 끝이 아니라는 것이므로 해당 문자열이 트라이 내부에 저장되어 있지 않다는 것이다. (트라이 내부에서 "찾아질 수"는 있으나 존재하지는 않는 것으로 판단하는 것이다.)
public boolean search(String str){
Node cur = this.root;
for (int i = 0; i < str.length(); i++){
char c = str.charAt(i);
if (cur.child.containsKey(c)){
cur = cur.child.get(c);
} else{
return false;
}
if (i == str.length() - 1){
if (!cur.isTerminal){
return false;
}
}
}
return true;
}
트라이의 구현 - 삭제
트라이의 삭제는 두 가지 케이스로 나누어질 수 있다.
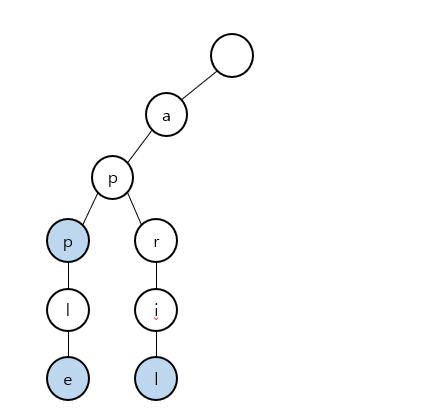
예시를 들기 위해 아래와 같은 트라이가 존재한다고 가정한다.
예시 트라이
여기서 "app"을 삭제한다고 가정하자. 일반적인 방법으로 노드를 삭제하다가는 아래의 le 노드들도 같이 삭제되어 apple 데이터가 손상될 위험이 있다. 위에서 탐색을 진행할 때 isTerminal의 상태를 통하여 해당 문자열의 존재 판단을 내린다고 하였다.
그렇다면 노드의 삭제 없이 "app"의 마지막 p 노드의 isTerminal을 false로 함으로서 탐색 과정에서 app은 존재하지 않게 되는 것과 마찬가지일 것이다.
이를 수행항 결과는 아래 사진과 같다.
"app"이 삭제된 모습
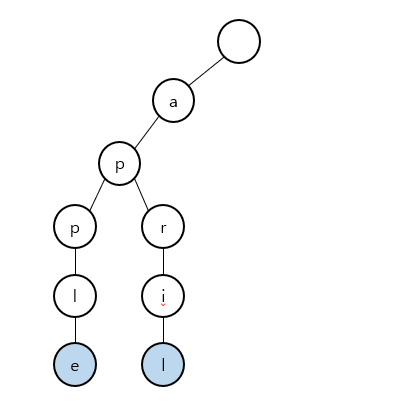
그럼 위의 원래 트라이에서 "apple"을 삭제하게 되면 어떻게 될까.
이 경우 "apple"과 "app"이 겹치는 부분은 놔두고 겹치지 않는 노드들을 제거하면 될 것 같다.
이때 각 노드들은 자신의 부모가 누구인지 알 수 없기 때문에 직접 타고 들어가는 노드 변수와 그 부모를 가리키는 노드 변수를 따로 두어야 하고, 바텀업 방식인 재귀로 구현하게 된다.
public void delete(String str){
boolean ret = this.delete(this.root, str, 0);
if (ret){
System.out.println(str + " 삭제 완료");
} else{
System.out.println(str + " 단어가 없습니다.");
}
}
public boolean delete(Node node, String str, int idx){
char c = str.charAt(idx);
if (!node.child.containsKey(c)){
return false;
}
Node cur = node.child.get(c);
idx++;
if (idx == str.length()){
if (!cur.isTerminal){
return false;
}
cur.isTerminal = false;
if (cur.child.isEmpty()){
node.child.remove(c);
}
} else{
if (!this.delete(cur, str, idx)){
return false;
}
if (!cur.isTerminal && cur.child.isEmpty()){
node.child.remove(c);
}
}
return true;
}
idx == str.length() 부분을 유심히 보도록 하자. 문자열의 끝 부분의 노드에서 isTerminal이 true로 되어있다면 이를 false로 바꾸어 트라이 상에서 존재하지 않게 한다.
그 이후에 해당 노드의 자식이 존재하는지 확인하여 노드의 자식이 존재할 경우 입력받은 문자열과 완벽히 겹치는 부분이 존재하며 추가적으로 파생되는 문자열이 존재하기 때문에 노드를 삭제하면 안된다.
만약 자식이 존재하지 않을 경우 파생되는 문자열이 존재하지 않으므로 공통 부분이 없다는 말이 된다. 따라서 삭제를 진행해도 문제가 없다.
나머지 파트들은 삭제할 문자열이 트라이 내에 존재하는지에 대한 확인과 재귀적으로 타고 들어가며 문자 하나하나를 확인하는 파트이다.
정리
트라이는 문자열 탐색을 약간의 공간을 희생하는 대신 빠른 시간 내에 수행할 수 있다는 장점을 가지고 있기 때문에 문자열과 관련된 문제에서 자주 사용될 수 있다.
전체적인 코드는 아래와 같다.
import java.util.*;
class Node{
HashMap<Character, Node> child;
boolean isTerminal;
Node(){
this.child = new HashMap<>();
this.isTerminal = false;
}
}
class Trie{
Node root;
Trie(){
this.root = new Node();
}
public void insert(String str){
Node cur = root;
for (int i = 0; i < str.length(); i++){
char c = str.charAt(i);
cur.child.putIfAbsent(c, new Node());
cur = cur.child.get(c);
if (i == str.length() - 1){
cur.isTerminal = true;
}
}
}
public boolean search(String str){
Node cur = this.root;
for (int i = 0; i < str.length(); i++){
char c = str.charAt(i);
if (cur.child.containsKey(c)){
cur = cur.child.get(c);
} else{
return false;
}
if (i == str.length() - 1){
if (!cur.isTerminal){
return false;
}
}
}
return true;
}
public void delete(String str){
boolean ret = this.delete(this.root, str, 0);
if (ret){
System.out.println(str + " 삭제 완료");
} else{
System.out.println(str + " 단어가 없습니다.");
}
}
public boolean delete(Node node, String str, int idx){
char c = str.charAt(idx);
if (!node.child.containsKey(c)){
return false;
}
Node cur = node.child.get(c);
idx++;
if (idx == str.length()){
if (!cur.isTerminal){
return false;
}
cur.isTerminal = false;
if (cur.child.isEmpty()){
node.child.remove(c);
}
} else{
if (!this.delete(cur, str, idx)){
return false;
}
if (!cur.isTerminal && cur.child.isEmpty()){
node.child.remove(c);
}
}
return true;
}
}
public class UserSolution {
public static void main(String[] args){
Trie trie = new Trie();
trie.insert("apple");
trie.insert("april");
trie.insert("app");
trie.insert("ace");
trie.insert("bear");
trie.insert("best");
System.out.println(trie.search("apple"));
System.out.println(trie.search("bear"));
System.out.println(trie.search("ben"));
System.out.println(trie.search("appear"));
System.out.println(trie.search("boolean"));
System.out.println();
trie.delete("apple");
System.out.println(trie.search("apple"));
System.out.println(trie.search("april"));
System.out.println(trie.search("ace"));
trie.delete("apple");
}
}