최단 거리 또는 최단 경로(Shortest Path)는 일반적으로 그래프상에서 이루어지는 개념이다.
그래프에서 한 노드를 기준으로 하여 다른 노드까지 이동하는데 걸리는 시간이 가장 적은 경로가 최단 경로 또는 최단 거리가 될 것이다.
이때 이동하는데 걸리는 시간을 수치적으로 나타낸 것이 가중치(weight)이고 최단 경로 문제는 다음과 같이 정의할 수 있을 것이다.
어떤 노드 Vi 에서 다른 노드 Vj 로 이동할 때 드는 가중치 W가 최소가 되는 경로를 구하는 문제
2. 활용처와 방법론
최단 경로 알고리즘의 활용은 매우 무궁무진하다. 일상적으로 가장 가까이서 찾아볼 수 있는 최단 경로 알고리즘의 활용처는 네비게이션이 될 것이다. 거리의 교차점을 하나의 노드로, 도로를 간선으로 추상화한다면 어떤 거리에서 다른 거리로 이동하는데 드는 최소 비용(여기서는 가중치가 시간이 될 것이다.)을 구하는 것이 될 것이다.
또한 우리가 사용하는 인터넷에서 패킷이 라우터를 거쳐 목적지로 가는데에도 최단 경로 알고리즘이 사용된다.(일반적으로 네트워크상에서 이동하는 시간이 가중치가 되며 시간이 음수가 될 수는 없기 때문에 다익스트라를 사용한다.)
이러한 최단 경로를 찾는 알고리즘은 크게 3가지가 존재하며 각각 다익스트라(Dijkstra), 벨만-포드(Bellman - Ford), 플로이드 와샬(Floyd - Warshall)알고리즘으로 불린다.
3. 다익스트라 알고리즘
다익스트라는 어떤 시작 노드 V에서 그래프에 존재하는 각 노드들에 대해 최단 거리를 구하는 알고리즘이다.
구현 방식은 DP + 그리디이며, 구현하는데 우선순위 큐를 사용할 수 있는 알고리즘이다.
기본적인 알고리즘의 순서는 아래와 같이 진행된다.
각 노드에 대해 최소 가중치를 저장해두는 DP 배열을 만들고, 그 내부를 모두 INF로 지정한다. 이때, 자기 자신은 이동하는데 어떠한 가중치도 들지 않으므로 0으로 설정한다.
각 노드들에 대하여 다음과 같이 수행한다.
갱신할 노드를 찾기 위한 거리 임시 변수를 선언하고 INF로 초기화한다.
이후 각 노드를 돌면서, 해당 임시 변수보다 작으면서 이미 방문하지 않은 노드를 찾는다.
INF보다 작은 노드를 찾는 이유는 가중치가 INF인 곳을 찾아 수행할 경우에 어떠한 값 갱신도 일어나지 않기 때문이다.(최소 가중치를 찾아야 하기 때문에)
이후 해당 노드를 방문하였다고 표시하고 해당 노드와 인접한 각 노드들에 대해 최소 가중치들을 갱신한다.
만약 해당 노드에서 인접한 노드로 가는데 드는 최소 가중치가 DP에 존재하는 최소 가중치보다 작다면 갱신하도록 하면 된다.
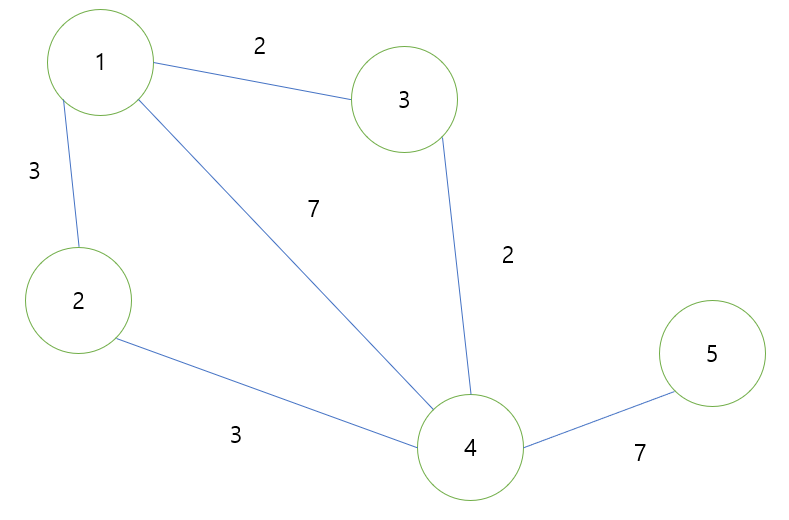
글로는 뭔가 이해하기가 힘드니 그림을 통해 한번 더 살펴보자
위와 같은 그래프가 있다고 가정하자 노드 1에서 출발할 때 각 노드들에 대한 최단 경로를 찾아야 한다.
DP table인 D을 만들어 자기 자신의 가중치는 0이기 때문에 0으로 초기화하고, 나머지 모든 노드들에 대해서는 무한대(INF)로 초기화한다고 하자.
임시 변수를 생성하여 DP table에서 그 노드까지 가는 거리가 INF가 아니고, 방문한 적 없는 노드를 찾는다. 여기에서는 1이 선택될 것이다. 그렇다면 이제 1과 인접한 노드들인 2, 3에 대해 distance이 갱신되어야 한다.
2까지 가는 최단 경로인 D[2]=∞이고, 1을 거쳐 2까지 가는데 드는 가중치는 D[1]+W12=0+3이 된다. 따라서 D[2]=min 에 의해 D[2] = 3이 된다.
이제 다른 인접한 노드인 3을 보도록 하자. 동일한 논리로 D[3] = \min(D[3], D[1] + W_{13})에 의해 D[3] = 2가 된다. 다른 인접한 노드인 4도 동일한 로직으로 인해 D[4] = 7이 될 것이다.
첫 번째 갱신이 일어난 이후의 DP-table인 D의 상태는 다음과 같다.
이제 다음 루프를 생각해보자. 1번은 이미 방문했으므로, 건너띄고 그 다음 2번 노드가 방문하지 않았으면서, INF로 설정된 임시 변수보다 적은 가중치를 가지고 있다.
2번의 방문 체크를 수행하고 2번과 인접한 1번과 4번에 대해 가중치 갱신을 시도한다.
1번의 경우 D[1] = \min(D[1], D[2] + W_{21})에서 D[1] = 0이기 때문에 갱신이 일어나지 않는다.
4번의 경우 D[4] = \min(D[4], D[2] + W_{24})에서 D[2] + W_{24} = 6이 되기 때문에 값 갱신이 일어나게 된다.
갱신이 끝난 이후의 그래프는 아래와 같다.
다음도 동일하게 3번이 선택된다. 3번과 인접한 1번노드와 4번 노드에 대해 값 갱신이 시도된다.
1번의 경우 D[1] = \min(D[1], D[3] + W_{31})에서 D[1] = 0이기 때문에 갱신이 일어나지 않는다.
4번의 경우 D[4] = \min(D[4], D[3] + W_{34})에서 D[2] + W_{34} = 4가 되기 때문에 값 갱신이 일어나게 된다.
갱신 이후의 그래프는 아래와 같다.
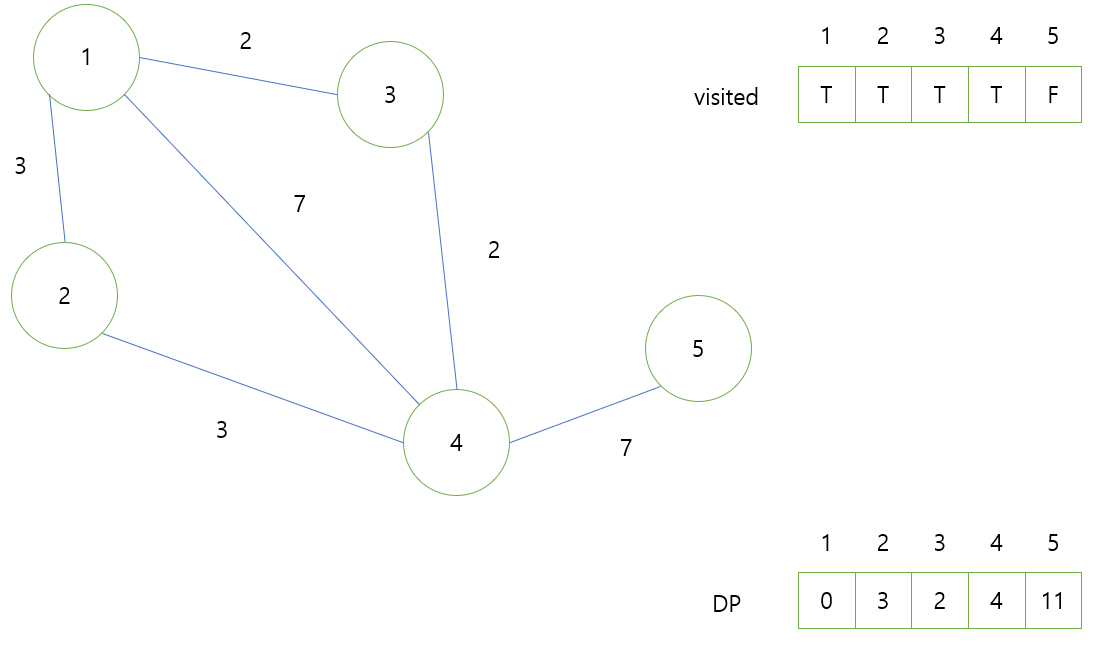
다음 루프로는 4번이 된다. 4와 인접한 노드 1, 2 ,3, 7에 대해 갱신이 시도된다.
1, 2, 3번은 모두 현재 DP에 저장되어 있는 값들이 더 작다는 것을 알 수 있다.
5번의 경우 D[5] = \infty로 D[5] = \min(D[5], D[4] + W_{45})에서 11로 값이 갱신된다.
갱신이 종료된 이후의 그래프는 아래와 같다.
마지막으로 5가 남았으며 5번 노드는 인접한 노드가 4이외엔 존재하지 않고, 4에서 역시 값 갱신이 일어나지 않는다. 따라서 갱신이 없이 종료되며 1번을 기준으로 각 노드에 대한 최단 경로가 모두 구해졌다.
각 과정에서 착각하면 안되는 것은 각 노드를 "시작점"으로 설정해서 하는 것이 아닌 1번에서 각 노드를 "경유해서" 가는 거리라는 것이다. 즉 위의 DP에 있는 각 값들은 1번 노드를 시작점으로 하였을 때 4번 노드로 가는 것의 경우, 1 -> 3 -> 4로 가는 경로가 4로 가장 최단 경로가 된다는 것이다.
해당 알고리즘의 구현은 아래와 같다.
// 알고리즘 - 최단 경로 알고리즘// 다익스트라 기본 구현import java.util.ArrayList;
publicclassMain{
staticclassNode{
int to;
int weight;
publicNode(int to, int weight){
this.to = to;
this.weight = weight;
}
}
publicstaticvoiddijkstra(int v, int[][] data, int start){
ArrayList<ArrayList<Node>> graph = new ArrayList<>();
for(int i = 0; i < v + 1; i++){
graph.add(new ArrayList<>());
}
for (int i = 0; i < data.length; i++){
graph.get(data[i][0]).add(new Node(data[i][1], data[i][2]));
}
int[] dist = newint[v + 1];
for (int i = 1; i < v + 1; i++){
dist[i] = Integer.MAX_VALUE;
}
dist[start] = 0;
boolean[] visited = newboolean[v + 1];
for (int i = 0; i < v; i++){
int minDist = Integer.MAX_VALUE;
int curIdx = 0;
for (int j = 1; j < v + 1; j++){
if (!visited[j] && dist[j] < minDist){
minDist = dist[j];
curIdx = j;
}
}
visited[curIdx] = true;
for (int j = 0; j < graph.get(curIdx).size(); j++){
Node adjNode = graph.get(curIdx).get(j);
if (dist[adjNode.to] > dist[curIdx] + adjNode.weight){
dist[adjNode.to] = dist[curIdx] + adjNode.weight;
}
}
}
for (int i = 1; i < v + 1; i++){
if (dist[i] == Integer.MAX_VALUE){
System.out.print("INF ");
} else{
System.out.print(dist[i] + " ");
}
}
}
publicstaticvoidmain(String[] args){
// Test codeint[][] data = {{1, 2, 2}, {1, 3, 3}, {2, 3, 4}, {2, 4, 5}, {3, 4, 6}, {5, 1, 1}};
dijkstra(5, data, 1);
}
}
4. 다익스트라 - 우선순위 큐
사실 굳이 저렇게 최소가 되는 간선을 일일히 탐색하지 않아도 된다. 시작점에서 가까운 노드들(시작점에서 해당 노드까지의 가중치가 적은 노드)을 우선순위로 택하여 뽑아낸다면, 결론적으로 시작 노드에서 모든 노드까지 최단 거리가 구해지기 때문이다.
가중치가 적은 것이 우선순위가 높은 데이터로 분류할 수 있으므로 여기서 우선순위 큐를 사용할 수 있다. 여기서는 최소 가중치를 먼저 나오게 해야 하므로 min-heap으로 구성하면 된다. 해당 방식은 visited를 사용하지 않는데 어차피 기존 경로보다 긴 경로가 나오면 무시하면 되기 때문이다.
// 다익스트라 우선순위 큐 사용import java.util.ArrayList;
import java.util.PriorityQueue;
publicclassMain2{
staticclassNode{
int to;
int weight;
publicNode(int to, int weight){
this.to = to;
this.weight = weight;
}
}
publicstaticvoiddijkstra(int v, int[][] data, int start){
ArrayList<ArrayList<Node>> graph = new ArrayList<>();
for(int i = 0; i < v + 1; i++){
graph.add(new ArrayList<>());
}
for (int i = 0; i < data.length; i++){
graph.get(data[i][0]).add(new Node(data[i][1], data[i][2]));
}
int[] dist = newint[v + 1];
for (int i = 1; i < v + 1; i++){
dist[i] = Integer.MAX_VALUE;
}
dist[start] = 0;
//create min heap(weight)
PriorityQueue<Node> pq = new PriorityQueue<>((x, y) -> x.weight - y.weight);
pq.offer(new Node(start, 0));
while(!pq.isEmpty()){
Node curNode = pq.poll();
if(dist[curNode.to] < curNode.weight){
continue;
}
for (int i = 0; i < graph.get(curNode.to).size(); i++){
Node adjNode = graph.get(curNode.to).get(i);
if (dist[adjNode.to] > curNode.weight + adjNode.weight){
dist[adjNode.to] = curNode.weight + adjNode.weight;
pq.offer(new Node(adjNode.to, dist[adjNode.to]));
}
}
}
for (int i = 1; i < v + 1; i++){
if (dist[i] == Integer.MAX_VALUE){
System.out.print("INF ");
} else{
System.out.print(dist[i] + " ");
}
}
}
publicstaticvoidmain(String[] args){
// Test codeint[][] data = {{1, 2, 2}, {1, 3, 3}, {2, 3, 4}, {2, 4, 5}, {3, 4, 6}, {5, 1, 1}};
dijkstra(5, data, 1);
}
}
5. 다익스트라의 시간복잡도
순차 탐색을 통한 다익스트라의 시간복잡도는 정점의 개수를 V, 간선의 개수를 E라고 지정할 때 O(V^2)를 가진다.
우선순위 큐를 사용할 경우, O((V + E) \log V)를 가진다. 이는 모든 정점 V에 대해 최단 거리를 가지는 노드를 찾는데 우선순위 큐의 특성 상 V \log V가 걸리고, 각 노드에 대해 이웃한 노드의 최단 거리를 갱신하는데 우선순위 큐의 갱신 시간 복잡도 특성 상 E \log V의 시간이 걸리기 때문이다.